利率有三种理解:
- 要求的回报率
- discount rates
- 机会成本
r = Real risk-free interest rate + Inflation premium + Default risk premium + Liquidity premium + Maturity premium.
理论上:(1 + nominal risk-free rate) = (1 + real risk-free rate)(1 + inflation premium)
实际上简化为:Nominal risk-free rate = Real risk-free rate + inflation premium
金融资产的收益有两部分:1)现金分红或利息支付;2)价格波动的收益。
平均数和持有收益率
普通的holding period return是:
平均收益率有数学平均和几何平均,几何平均是:
通常来说数学平均会高估,除非底层回报率都是相同的。
几何平均表现出了compouding 的特性,在多周期的报告上比较有用;数学平均则对于单周期比较有用。
Harmonic mean:
如果data是rates或者ratios(比如P/E)会比较有用,极端值影响较少。特别是对于base固定但是ratio不同的情况有用,比如cost averaging(例如定投)。

$ 数学平均\times Harmonic平均={几何平均}^2 $
而且 $ H平均 < 几何平均 < 数学平均 $
trimmed平均:去掉最大去掉最小
winsorized平均:上下限替换。
money加权和时间加权回报
money加权收益率就是IRR:
因为不同时间投入不同的钱造成的加权不一样,所以遇到比较的时候不太能用。
时间加权,特点是对于现金的投入和赎回不敏感,有三步:
- Price the portfolio immediately prior to any significant addition or withdrawal of funds。根据投入或赎回的时间切分成sub-period
- 计算每个period的holding period return
- Link or compound holding period returns to obtain an annual rate of return for the year。如果时间超过1年,用几何平均来获取年回报率。
第一步在实际里很难做,但是如果组合是being valued frequent, regular intervals, particularly if additions and withdrawals are unrelated to market movements,那这个近似值就会很精准。比如365天天天定价,那就可以先算每天的持有收益率,然后 $ (1+R_1)\times(1+R_2)\times…\times (1+R_{365})-1 $ 得到时间加权年回报率。如果不止1年,那就先算每个年的时间加权年回报率,再几何平均。
例如以下例子:
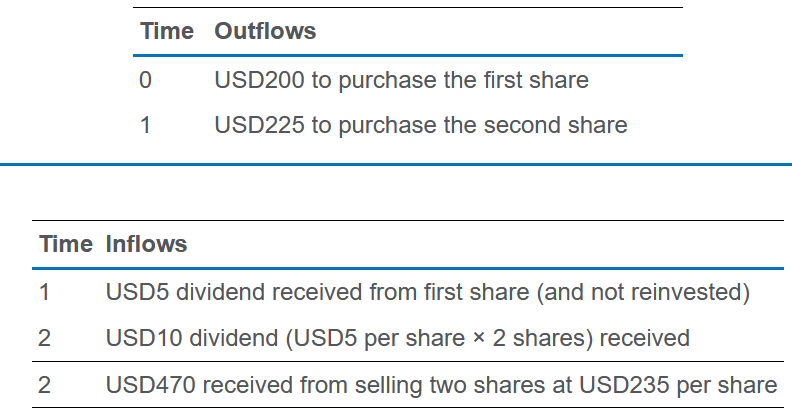
第一年的持有收益率是 $ (5+225-200)/200 = 15\% $
第二年的持有收益率是 $ \frac{(5\times 2+235\times 2-\boldsymbol{225}\times 2)}{\boldsymbol{225}\times 2} \approx 6.67\% $
然后就是第三步: $ (1+时间加权年回报率)^2 = (1+15\%)(1+6.67\%) $
年化收益率
quoted年利率 $ R_s $,每年m个复利周期,一共N年。
对于不常见的利率,比如15日0.4%,就这样算:$(1+0.4\%)^{365/15}-1=10.02\%$
比如18个月20%,次方数是一年的12个月除以18个月:$(1+20\%)^{2/3}-1$
局限性:这样年化是假设能够每次都投到相同的利率;特别是对于短周期的的来说,不一定能做到。
continuously compounded return:
比如一个星期的持有收益率是4%,那么所谓“一周连续复利回报率”就是$ln(1.04)$。根据简单的数学推理可知:
其他
gross return:没有扣除管理费、保管费、税和其他management and administration支出之前的收益;但是交易费是要扣的。
net return就是扣了这些management and administration支出之后的。到这里就是pre-tax nominal income。
再扣除any allowance for taxes on dividends, interest, and realized gains就是after-tax nominal return。1
real return:
比如税率是20%,pre-tax nominal收益率是3%,通胀率是2%,那么after-tax real return就是 $ \frac{(1+3\%\times(1-20\%))}{1+2\%}-1=0.39\% $
杠杆收益率:Rp是产品收益率,VE是自己的钱,VB是借来的钱,rD是借来的钱的利率
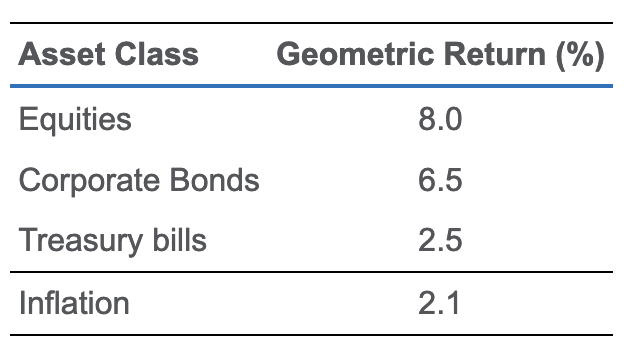
注意⚠️:如下图,如果要算risk premium,那就不用管inflation premium,因为所有的资产都面临相同的通胀premium,直接用$ \frac{1+\text{nominal return}}{1+\text{nominal risk-free return}}-1 $来算。
货币时间价值(固定收益和权益)
Yield-to-maturity:the rate of return on a bond or loan
固定收益资产的现金流有三种类型:
- discount,支付一个PV,在到期时获得一个FV
- 定期利息:支付一个PV,固定间隔获得利息(PMT),到期时获得利息(PMT)和本金
- Level Payments:支付一个PV,固定间隔获得A(同时包含本金和利息)
Discount
也叫 zero-coupon bond 。
定期利息
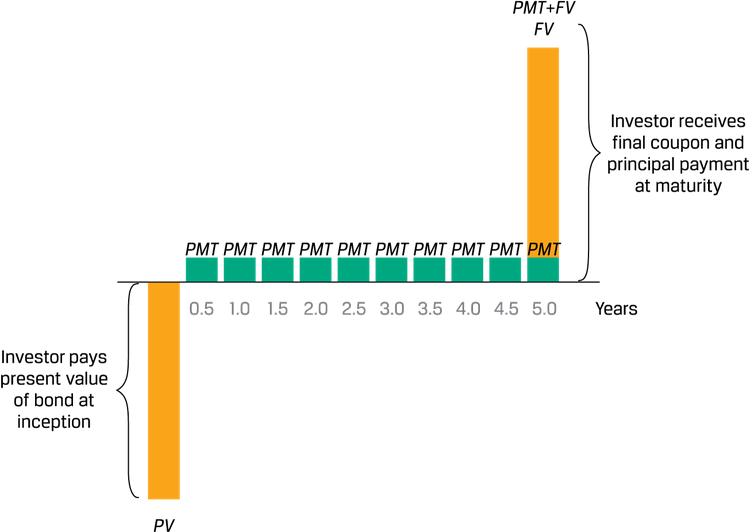
永续债perpetual:
年金 Annuity
比如计算房贷,PV就是现在要贷的钱。用计算器的话,PV就是现在要贷的钱,N是Payment总次数(比如月供,30年,就是360),I/Y直接输年利率,FV是0;需要设置P/Y是12。
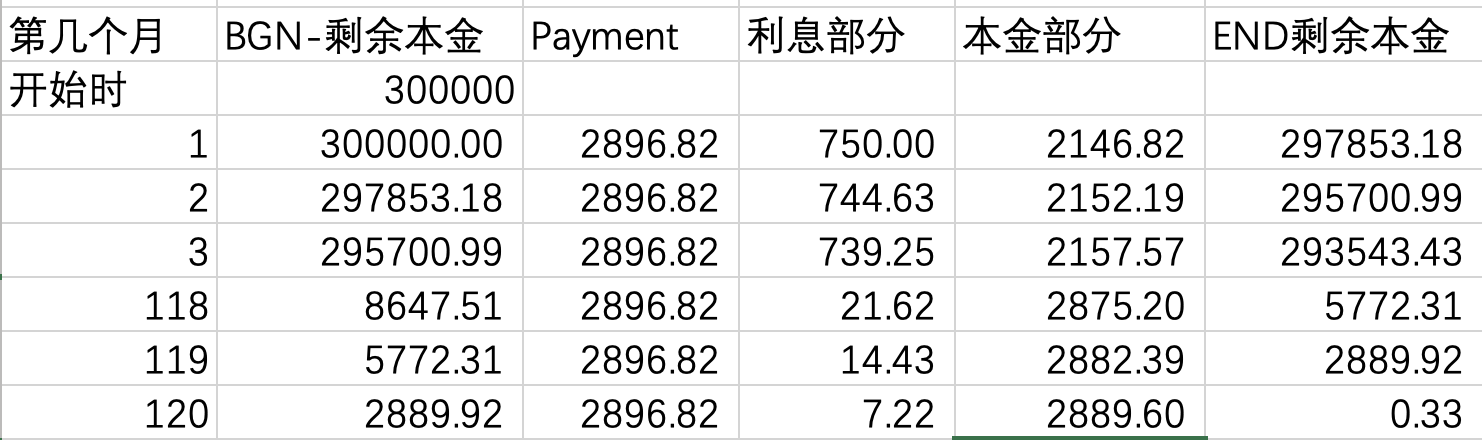
principal amortization and interest breakdown:
第一个月的利息是principal×利率(月利率);principal amortization是算出来的PMT减去利息;然后用principal-principal amortization算剩余本金。第二个月的利息是剩余本金×利率,其他同上。所以Monthly Principal Repayment会越来越多,利息则越来越少。
比如10年,PV=30万,利率3%。用计算器可以得到PMT=2895.82。那么前几期和最后几期的:
equity
现金流有三种:
- 固定分红,支付PV之后获得固定的periodic分红(D)
- 固定增长率分红:支付PV之后,第一期的分红是 $ D_{t+1} $ ,然后分红以固定增长率g增长
- 可变增长率分红:支付PV之后,第一期的分红是 $ D_{t+1} $ ,但是后续的增长率不固定
固定分红的情况下跟perpetual一样, $ PV=D/r $
固定增长率的情况, $ PV=\frac{D_t(1+g)}{r-g}, \text{with } r-g >0 $
可变增长率的情况,假设是两段式:
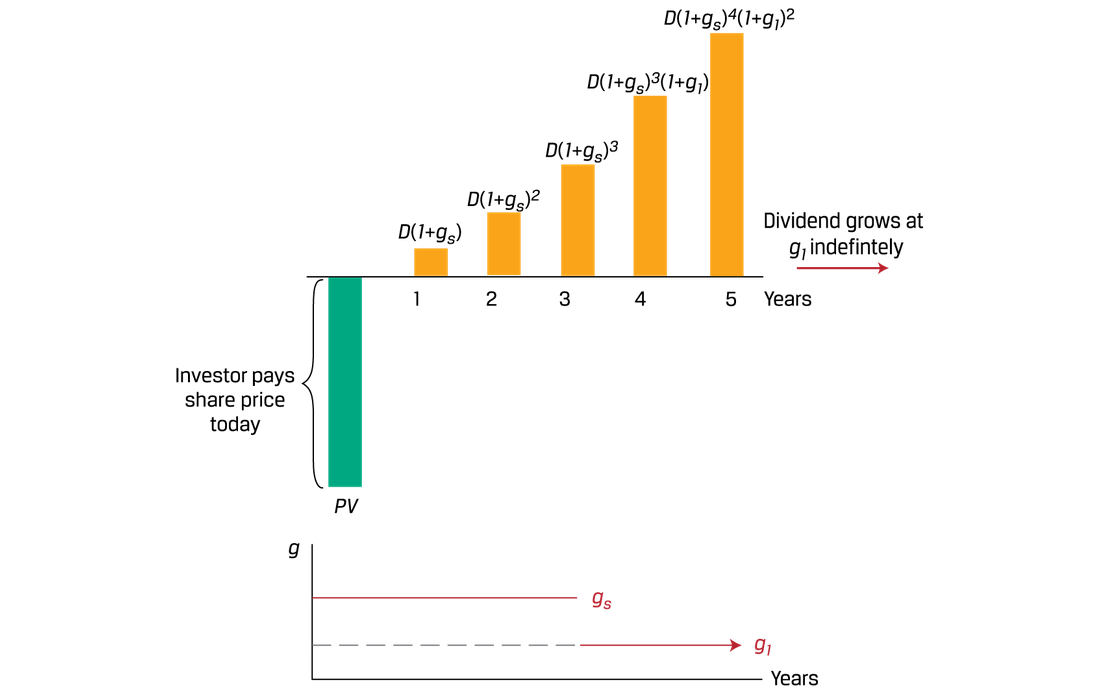
注意,两段式的第二段(增长率较低的那一段)的折现倍率是n;所以如果1到3年高增长,第4年开始低增长,是:
隐含收益率和增长率
固定收益资产
固定收益资产的YTM就是隐含收益率。
discount的隐含收益率是
直接使用计算器的CF和I/Y都是不对的:
 需要先算出利息的FV,然后加到93.091上,然后再算出这个值的PV:
需要先算出利息的FV,然后加到93.091上,然后再算出这个值的PV:
- N=2,I/Y=2,PV=0, PMT=2, 算FV=4.04
- 4.04+93.091=97.131,FV=93.171,PV=-100,PMT=0,算I/Y=-1.4449
注意这个题不是算后五年的YTM,而是算这两年的收益率,那么:
Equity
固定增长率:
隐含增长率:
$ \frac{D_t}{E} $ 叫做dividend payout ratio。使用预测的下一期earnings per share,可以简化为:
cash flow additivity principle
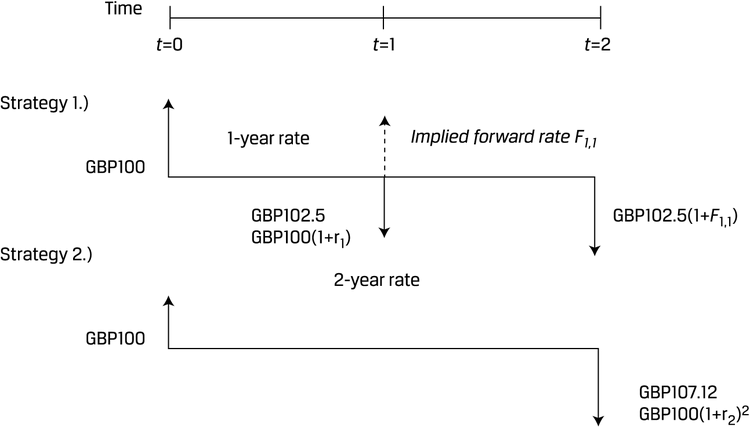
IFR
Implied Forward Rate的算法是:
forward interest rate也可以称作breakeven one-year reinvestment rate in one year’s time。
如果给出PV,就要先算r再算forward interest rate:
 以计算2022年5月31日的1y1y IFR为例:
以计算2022年5月31日的1y1y IFR为例:
- 用计算器分别计算1y和2y的收益率
- N=1, PV=-98.028, PMT=0, FV=100, 计算I/Y=2.011670%
- N=2, PV=-95.109, PMT=0, FV=100, 计算I/Y=2.529027%
- 应用公式 $ (1+r_1)(1+IFR{1,1})=(1+r_2)^2 $ 算出IFR
同理可确定不同货币的forward exchange rate,不过要注意使用连续复利(e)。

期权定价
- t=0时标的是40元;=1时有可能是56,有可能是32;求期权价格c0
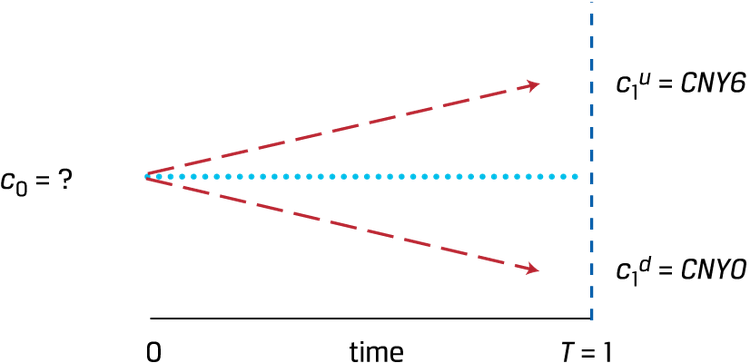
首先要构造一个portfolio使得t=1时无论哪种情况现金流都一样。这里需要算的是购买多少unit的标的:
算出x之后可以得到t=1时的现金流,就可以算t=0时的c0了:
其中x又叫做hedge ratio。
分位数算法
所以第4个5分位就是:
Coefficient of Variation
简称CV, $ CV=\frac{s}{\bar X} $ 。CV越大越风险。
偏度峰度
Skewness偏度,正偏度指frequent small losses和a few extreme gains;负偏度反过来:
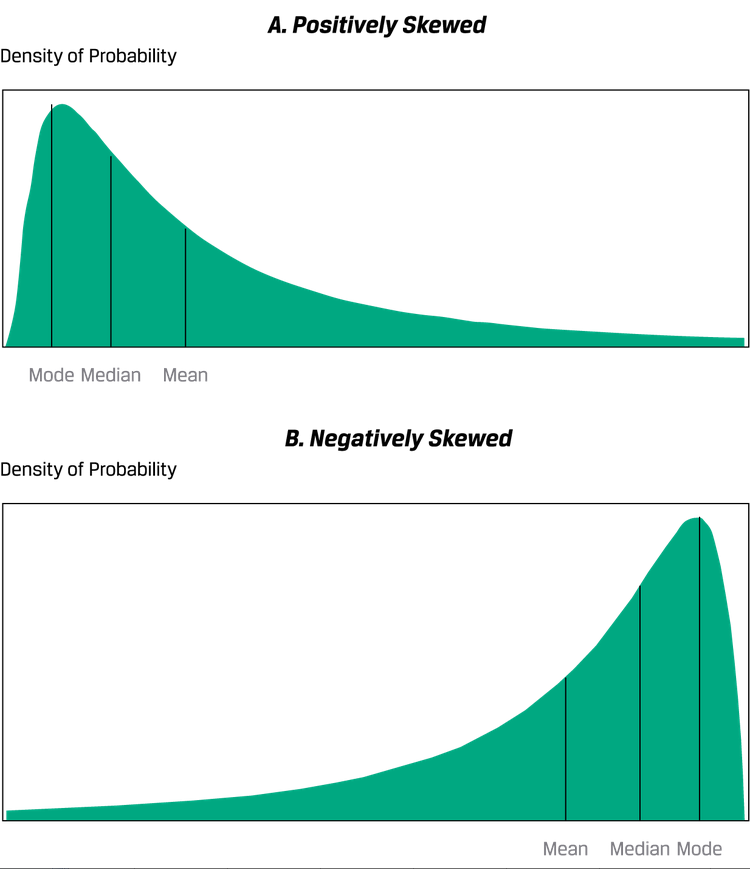
投资者通常会被正偏度吸引,因为平均数比中位数大。
峰度:xx个标准差之外的总probability的占比。
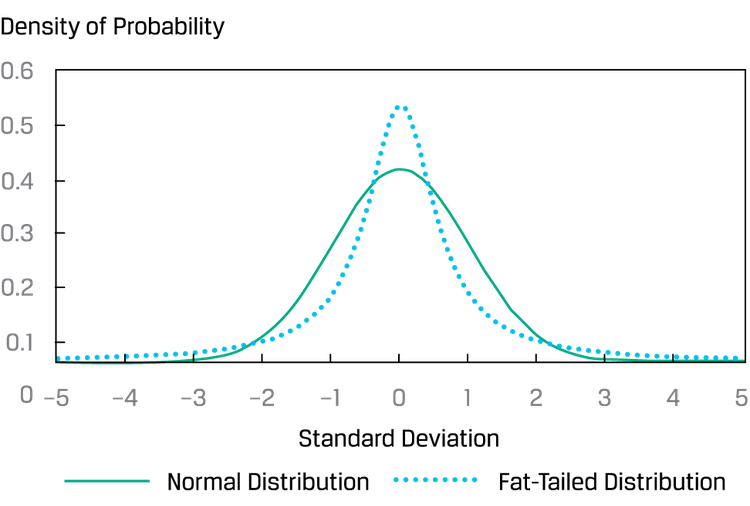
fat-tail 对应的是 leptokurtic(尖峰);thin-tail对应的是platykurtic(平峰);标准正态的是msokurtic(峰度3)。fat-tail可以理解为风险更高。
通常会计算excess kurtosis(与标准正态的3对比);对于样本大于100的:
Correlation
Sample covariance:
如果X大于平均值时Y也大于平均值,X小于平均值时Y也小于平均值,那么covariance就会是正的。
sample correlation coefficient,去掉了单位:
会显示线性相关的强度:
- $ -1 \le r_{XY} \le 1 $
- 0代表没有线性关系
- 1代表强正线性相关;-1代表强负线性相关
注意,可能存在非线性相关,但是这个指标不能反映这个事实:
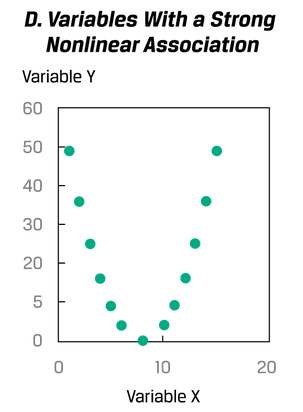
以及对极端值很敏感,需要考虑是否排除(用点阵图来预览);相关不代表因果。
spurious correlation(虚假相关),有三种情况:
- 只在特定数据集中存在
- 计算时混入了第三个变量
- 两个变量间的相关是来自于它们各自跟第三个变量的关系而不是direct2
相同的平均数、标准差和相关性不能够完全确定整个变量分布是怎么样的。
Expected
Expected的是forecast,是population。
用计算器:DATA,X输入X,Y输入概率(百分数,不能输小数形式)
Conditional

从右向左计算,无论是conditional expected还是conditional variance。
贝叶斯公式 Bayes’ Formula
贝叶斯公式是用来在获得新信息的时候调整已有的结论的方法。
更新后的概率叫做posterior probability。
如果 prior probabilities 都相等,就叫做diffuse priors,那么事件的概率就完全由信息决定。
Portfolio Expected
expected return on the portfolio:加权平均回报率:
Covariance的公式是(没什么用,看看就行):
Portfolio variance(也没什么用,看看就行):
假设给出以下信息,则可以开算:

Covariance Matrix: 注意图里面的数字的单位都是%的平方;比如400是指0.04;在练习中问covariance的时候也是回答400而不是0.04。

资产分散带来的风险降低:如果portfolio的构成都是independent的,cov就会都是0,那portfolio variance比起非independent时会更小;如果是负相关的,cov小于0,variance更小。
Correlation:
用Covariance Matrix可以直接得出Correlation Matrix。与前面的相同,上下限是 $ [-1,1] $,绝对值越接近1就越线性相关。
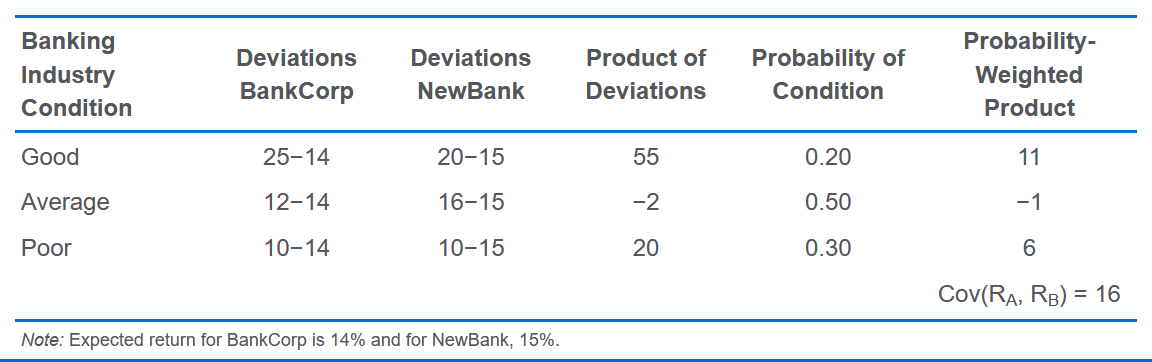
Joint Probability Function
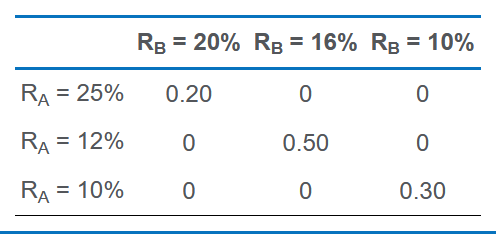
根据这个表可以算出A的平均回报是 $ 0.2\times 25\% + 0.5 \times 12\% + 0.3 \times 10\% = 14\% $,B同理得15%。然后构造下表,解释第一行:
- Good对应第一个表的25%和20%
- 先算两个与平均值的差,25-14是25%减平均值14%
- 将两个差相乘,再乘以权重0.2
算出所有情况之后加起来就是Cov。
独立
如果两个变量独立,那么 $ P(XY)=P(X)P(Y) $
如果两个变量uncorrelated,那么 $ E(XY)=E(X)E(Y) $
mean–variance analysis
有三个假设:
- 风险厌恶
- 最大化预期utility或satisfaction
- 或:
- 回报是正态分布的
- 投资者的效用方程是二次的
如果都满足,那么就是exactly;如果第三条不满足,就是approximately。
如果只考虑downward risk(shortfall risk),可以用safety-first rules。
最低可接受收益是 $ R_L $,那么投资者的目的就是选择 $ P(R_p<R_L) $ 最小的那个组合;return是正态分布的情况下,相当于选出一个最大的:
每个投资组合return低于 $ R_L $ 的概率是 $ NORM(-\text{SFRatio}) $ 。当 $ R_L = R_{\text{risk free}} $ 的时候,就成了夏普比率。
value at risk (VaR):特定时间内、特定可能性下,可能损失的最小金额。比如95 percent one-day VaR就是一天内有0.05的可能损失至少这个金额。
Stress testing and scenario analysis refer to a set of techniques for estimating losses in extremely unfavorable combinations of events or scenarios。
Lognormal 对数正态分布
偏度是正的,右尾很长。
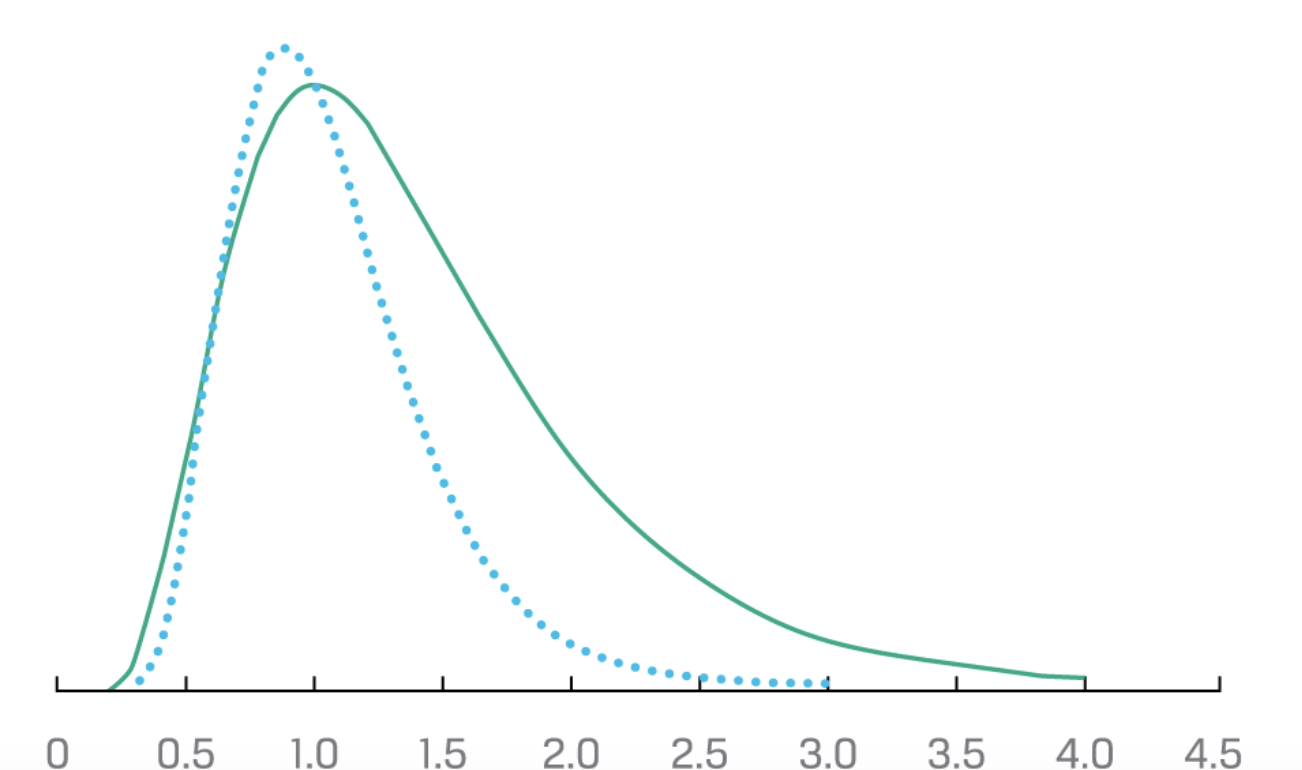
- 如果continuously compounded return是正态分布的,那么未来的股价必定lognormal
- 即使continuously compounded return不是正态分布,如果满足中心极限定理,那未来股价也可以lognormal。
i.i.d:回报率是independently and identically distributed;independence导致不能用过去的returns预测未来return;identical导致平均数和方差不变。从而有:
这是continuously compounded return的正态分布的参数,可以用来算股价(lognormal)的参数。
volatility是continuously compounded returns的standard deviation
给定daily volatility假设为0.01,那么年的volatility就是 $ 0.01\times \sqrt{250} $ 。通常的计算过程:获取日持有收益率,转换为continuously compounded daily returns,然后计算标准差(即daily volatility):
计算器用STAT的1-V,但是DATA需要自己转换成ln;1-V算出来的是daily,需要转换成年( $ E(r_{0,T}) = \mu T $ )。
蒙特卡洛模拟和bootstrap模拟
没时间记了。
bootstrap是抽了还放回去,jackknife是抽了不放回去。
Sampling method
probability sampling:pop里面每个element都有相同的机会被选中
non-prob samp:sampler’s judgment or the convenience to access data会影响概率。
Prob
简单随机抽样。系统抽样(每k个抽一个)。
抽样就会有sampling error。统计量也是随机变量,存在分布。统计量的抽样分布是统计量在从同一总体中随机抽取的相同大小的样本计算时可以假设的所有不同可能值的分布。
Stratified Random Sampling分层随机抽样。先把population分组,然后 $ \frac{每组样本数}{总样本数} = \frac{每组大小}{pop大小} $ 。
Cluster抽样,将pop分成小cluster,每个cluster其实都是pop的一个缩影;以cluster为单位进行简单随机抽样。one-stage是选中的cluster的所有member都作为样本;two-stage是选中的cluster再抽sub-sample。
Non-prob
方便抽样(Convenience Sampling)。
Judgmental Sampling。based on a researcher’s knowledge and professional judgment
中心极限定理及相关
只要样本量够大,那么分布就会近似正态,参数是 $ \mu $ 和 $ \sigma^2/n $ 。
the standard error of the statistic指sample statistic的标准差。
sample mean的standard error就是 $ \sigma_{\bar X} = \frac{\sigma}{\sqrt{n}} \text{或} s_{\bar X} = \frac{s}{\sqrt{n}} $ 。
实践中很难知道pop的方差,所以都会用样本方差:
总而言之,中心极限定理说的是,只要样本量够大:
- $ \bar X $ 的分布近似正态
- $ \bar X $ 的分布的均值等于pop的均值
- $ \bar X $ 的分布的方差等于pop的方差除以样本大小

用1-V算 $ \sigma $ ,再除以 $ \sqrt{10-1} $ 。计算器算的s不是standard error,是sample standard deviation。
假设检验
总表:

相关内容:笔记
independent samples(not paired)用difference in mean;
dependent samples(paired)用mean of differences。
Type I:H0是真的但是reject了;Type II:H0是假的但是没有reject。
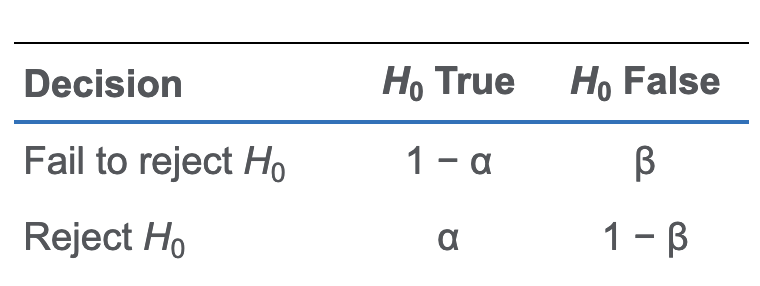
Power of test是 $ 1- \beta $ 。
非参数检验
前一节的检验都有两个特征:1)检验的是parameter;2)有一些前提假设(比如正态分布)。
非参数检验有以下场景:
- data不满足分布要求
- 有极端值
- 是rank或者ordinal数据
- 不是parameter
独立性检验
Corr的参数检验也称Pearson correlation/bivariate correlation,是为了检验两个pop之间是否存在线性关系(correlation coefficient)。
基于 sample correlation 的公式 $ r = \frac{s_{XY}}{s_Xs_Y} $ ,如果X和Y都服从正态分布,则用t检验 $ H_0: \rho = 0 $ :
自由度是n-2。样本量越大,reject所需的r越小;r越大,实现所需的显著性所需要的n越小。
非参数检验有Spearman rank correlation coefficient:
- 将sample X从大到小排列,最大设为1,第二是2,如此类推;如果两个数相等,那就设为平均值(比如第三和第四相等,那就都设置为3.5);Y也是这样操作
- 计算每对值的rank差别 $ d_i $ (这里的每对是恢复了原来的排序的,所以存在差别)
示例:
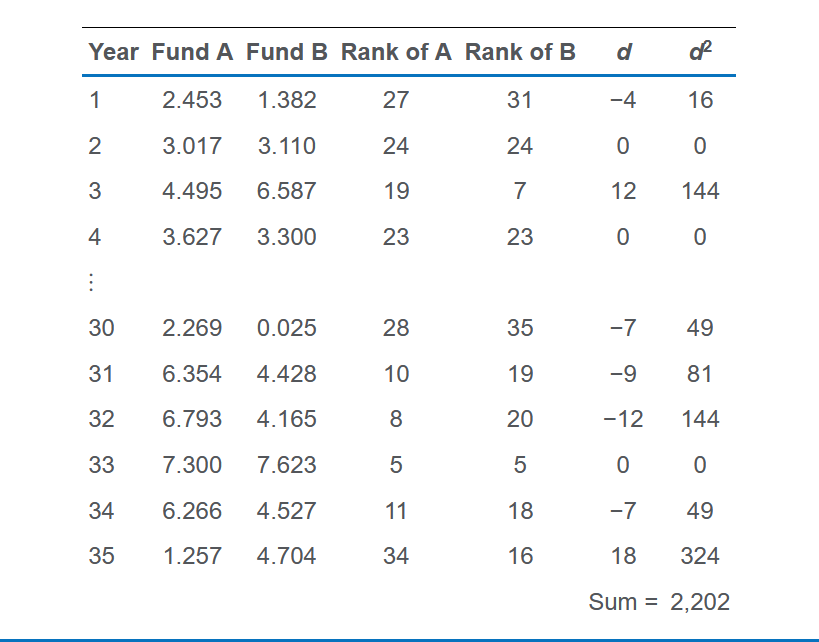
对于n大于30,就可以将 $ r_s $ 代入 $ t= \frac{r\sqrt{n-2}}{\sqrt{1-r^2}} $ 中做检验;否则需要一个特殊表格。
如果是categorical或者是离散数据,就没办法用前面两种方法来判断独立性。
结合示例来看:
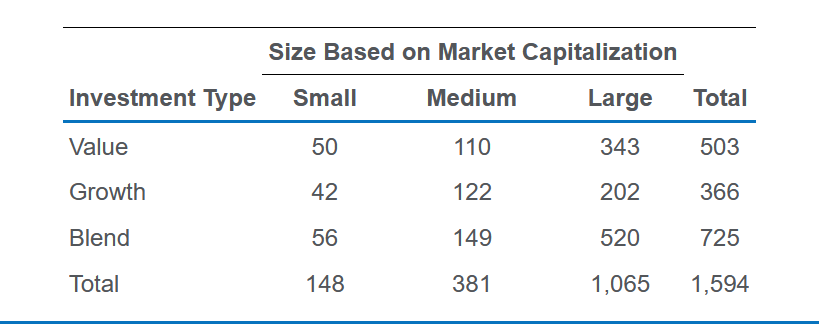
分类1有3种,分类2有3种,所以m=3×3=9; $ O_{ij} $ 是每个格子(sum的那些除外)的值; 一个 $ O_{ij} $ 对应的 $ E_{ij} $ 是这个格子的行sum乘以列sum除以总sum。例如small-cap value的 $ E_{ij} $ 是 $ \frac{503\times 148}{1594} = 46.703 $
算出来用卡方检验,自由度是 $ (n_1 - 1)(n_2 -1) = 2 \times 2 $ ,注意检验是单侧的。
(简单)线性回归
因变量Y的方差和叫做 sum of squares total (SST) 。
b0是intercept,b1是slope coefficient,这俩叫做回归系数(regression coefficients);$ \epsilon $ 是误差(error)。
注意, $ \epsilon $ 是sample和pop之间的;而 residual 是sample和当前line之间的。
目的是找到最小方差的那条线,所以又称ordinary least squares (OLS) regression;用 residual 来说就是最小化 $ \Sigma{e_i^2} $ ,sum of squares error (SSE)。 residual的单位与Y相同。
计算(都用计算器算,这里随便看看):斜率系数是X,Y的covariance除以X的variance:
需要满足的前提:
- 线性关系
- 同方差(Homoskedasticity):对于所有observations,residual的方差相同
- XY互相独立
- residual是正态分布(或者是大样本)
sample covariance就是X,Y的协方差除以n-1:
X不能是random的,但是residual最好是random的;如果residual跟X看起来存在关系,则可能XY不是线性关系,或者XY不是互相独立:
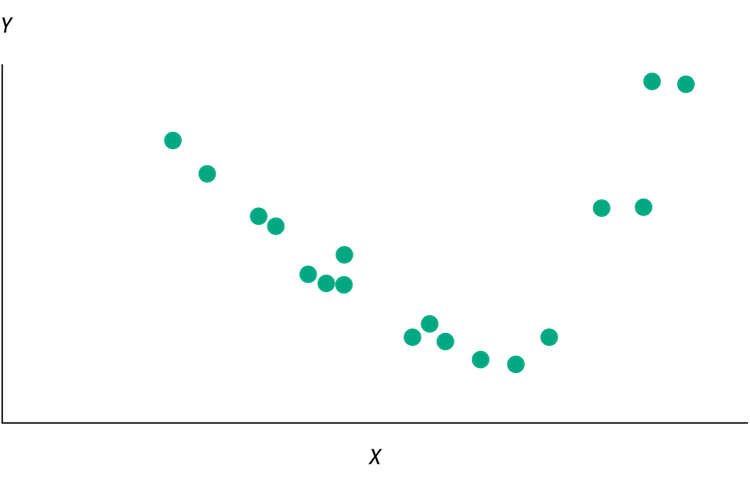
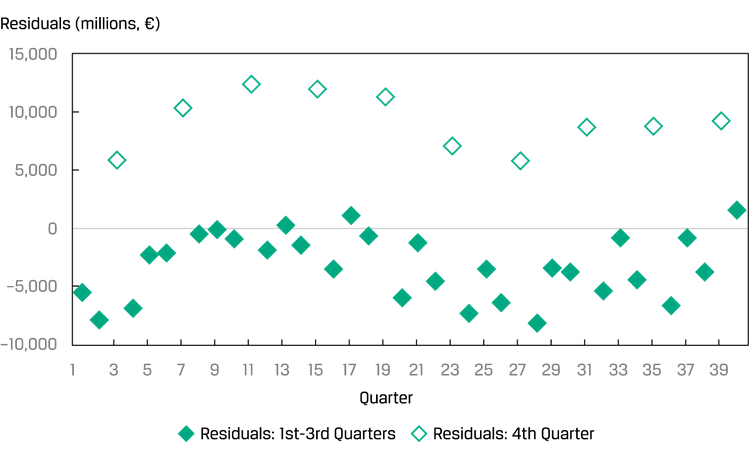
不满足前提2的举例:Y是利率,X是通胀率,中央银行在中间的某个节点进行了干预控制利率,就会导致方差不同:
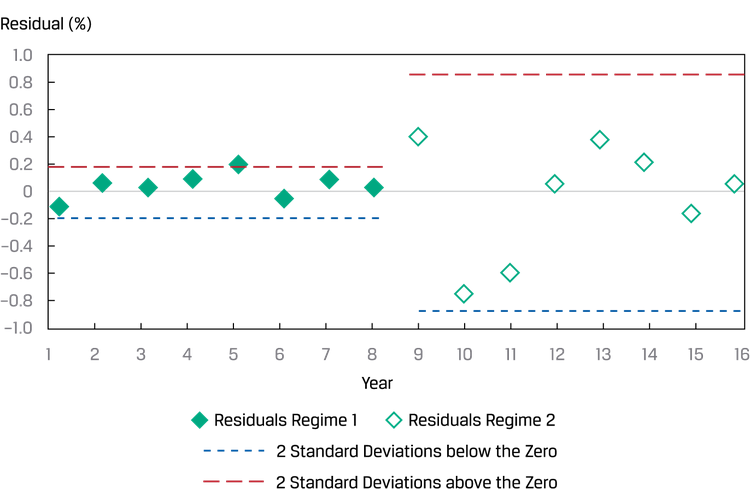
模型效果检验 Goodness of Fit
sum of squares regression(SSR):
SSR是explained variation,所以是hat - bar;SSE是unexplained variation。
coefficient of determination( $ R^2 $ ):
$R^2 = \frac{\text{SSR}}{\text{SST}}$
在计算器中,线性回归的r的平方就是 $ R^2 $ 。
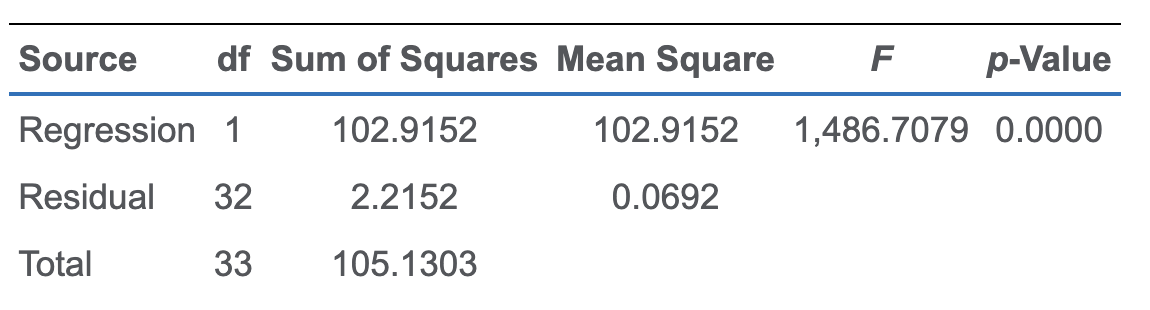
$ R^2 $ 是描述性的,如果要检验统计上有意义,就要做F检验。
null和alt:
F检验的值是SSR和SSE各自根据自由度调整之后相除;SSR除以自由度叫做mean square regression (MSR);SSE除以自由度叫做mean square error (MSE)
MSR的自由度是X的个数k,这里是1;MSE的自由度是n-k-1,这里是n-2。
$s_e = \sqrt{MSE}\\
MSE=SSE/(n-k-1)\\
MSR=SSR/(k)$
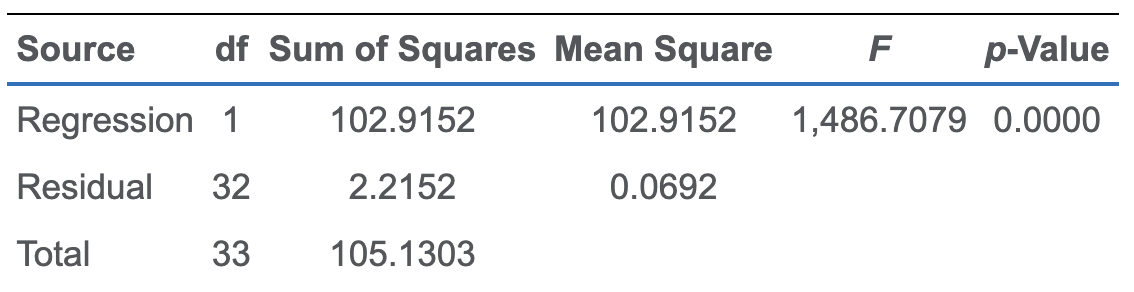
这个F检验是单侧的,reject区域在右侧——希望explained的比unexplained的多。
斜率系数检验
比如想要检验一个股票是否是平均系统性风险。相当于检验single mean,用t检验。
有一个假设的pop的斜率 $ B_1 $ ,t检验值:
$ s_{\hat{b}_1} $ 是standard error of the slope coefficient(斜率系数的标准差),是 model’s standard error of the estimate ( $ s_e $ )除以X的标准差:
特点
检验斜率是否为0的t检验的值等于检验XY的corr的t检验。也就是说以下两个是等价的:
- $ H_0: \hat{b}_1 = 0 $
- $ H_0: \rho = 0 $
- 只要等号、不等号的方向相同、数字相同,这两个就是等价的
所以用计算器的r带入 $ t= \frac{r\sqrt{n-2}}{\sqrt{1-r^2}} $。
同时,检验斜率是否为0的 t 的平方等于检验 拟合度的F值。
截距检验
indicator variable(发生了事件就1,否则是0的变量)的假设检验是相同的。
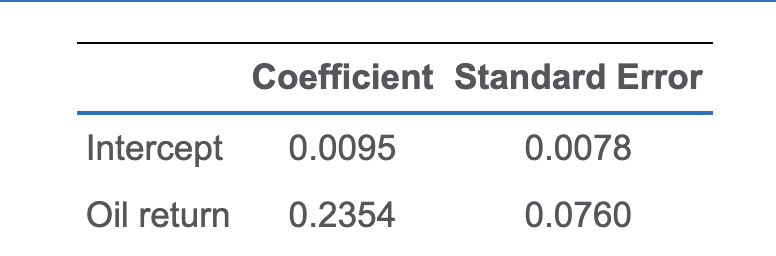
例题

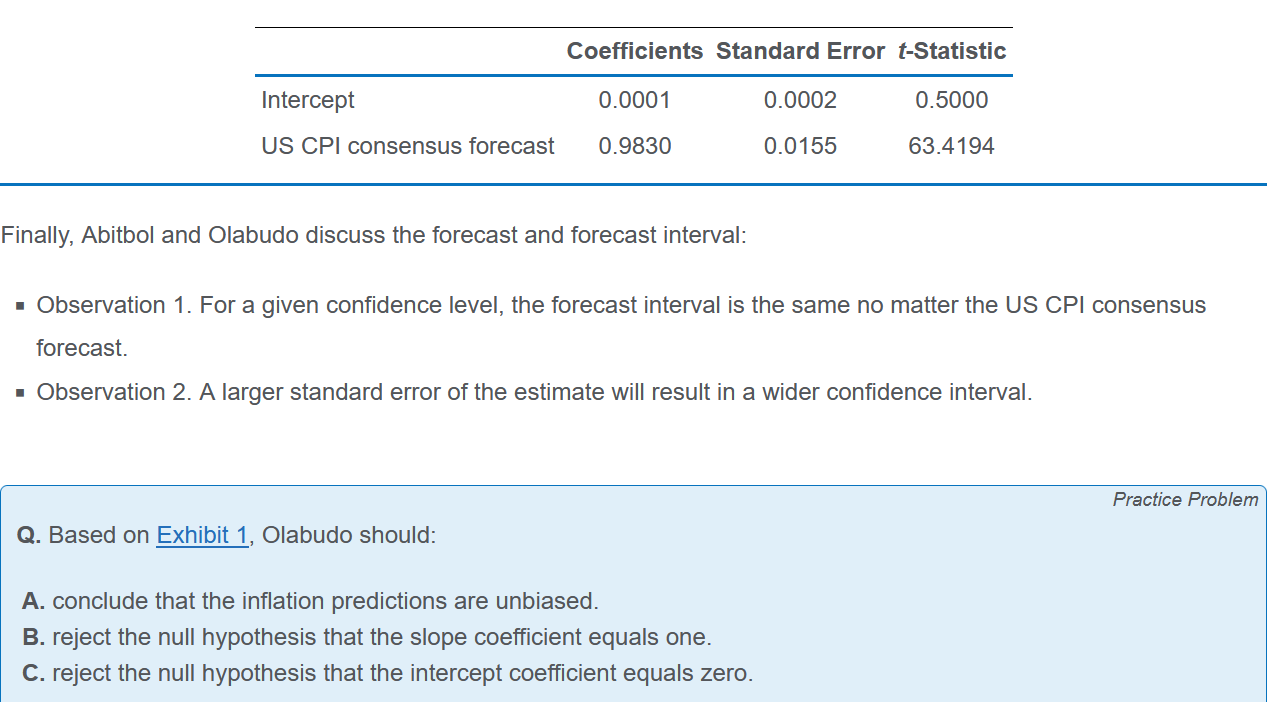
此处使用的是 $ t=\frac{\hat{b_1}-B_1}{s_{\hat b}} $:
- $ \hat{b_1} $ =0.9830, $ B_1 $ = 1
- $ s_{\hat b} $ 就是途中第二行的standard error
检验基本上都是coefficient减去目标值除以standard error:

p值
p值是拒绝null的最小的显著性水平。如果p=0.005而显著性是0.5时,就可以拒绝。显著性是percent,0.5%等于0.005
ANOVA
analysis of variance表格:

Y的方差是SSE除以n-1。
standard error of the estimate( $ s_e $ )就是MSE开根号;越小,模型越fit。
F和 $ R^2 $ 都是relative的,而 $ s_e $ 是绝对的。
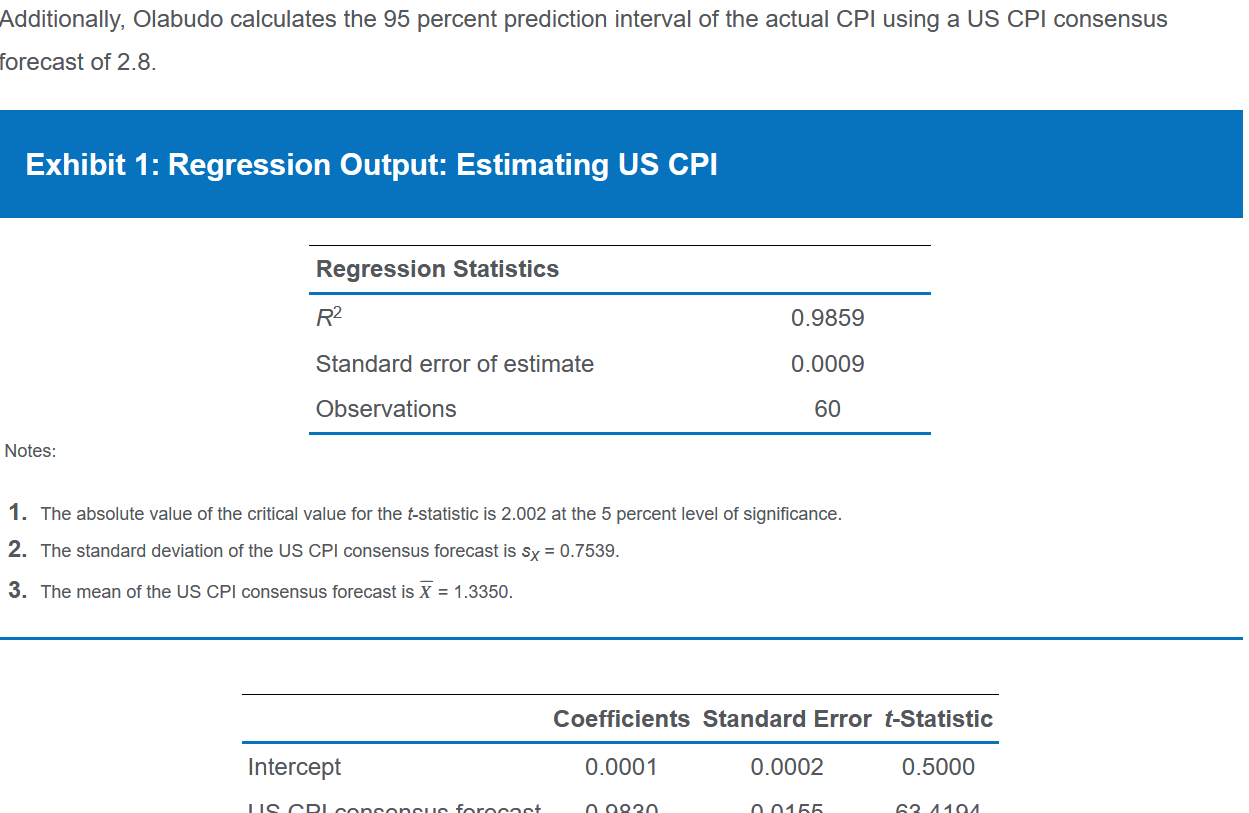
prediction
预测会存在方差:
预测的X与均值相差越小,方差就越小;样本量越大,方差越小;拟合越好,方差越小。
得到标准差之后就可以得到预测区间(interval):
线性回归参数转换
- log-lin(ln Y,X)
- lin-log
- log-log
log了就变成relative change了。log-lin和lin-lin不能直接对比,因为Y的单位不同了;相反,lin-log可以和lin-lin对比。
选择哪种,需要对比 $ R^2 $ 、 F检验以及 $ s_e $ ;最关键的是residual是否表现出pattern——目的是residual是random的。
Fintech
与投资相关的fintech部分:analysis of large datasets;analytical tools比如AI。
Big data的特征:volume大;velocity(产生速度)快;variety多。用于预测时,还有一个veracity:the credibility and reliability of different data sources。
Big data来源:金融市场、商业、政府、个人、传感器、IoT(物联网)。
Alternate data的主要来源:个人、商业过程、传感器。
ML algorithms aim to “find the pattern, apply the pattern.”
ML需要将dataset分成三个:training、validation、test。最大的限制是需要大量的数据来训练。需要留意overfitting和underfit,一个是把noise当真了,一个是把真的当noise了。
ML通常分三类:
- 监管学习:根据标注了的训练数据寻找model
- 无监管学习:数据没有标注
- 深度学习(神经网络)
Data处理方法:
- capture
- curation(在清理过程中保持质量和准确性)
- storage
- search
- transfer
对于文本这种非结构化数据,需要做文本分析(text analytics)。经典的包括自然语言处理(NLP)。